Les DRH déploient l’IA générative dans leurs processus d’évaluation à un rythme inédit. De nombreuses ETI européennes l’utilisent déjà pour rédiger plus vite des entretiens annuels mieux formulés. Le problème : un texte plus fluide ne corrige pas un jugement biaisé. Il le rend plus crédible.
Les DRH déploient l’IA générative dans leurs processus d’évaluation à un rythme inédit. De nombreuses ETI européennes l’utilisent déjà pour rédiger plus vite des entretiens annuels mieux formulés. Le problème : un texte plus fluide ne corrige pas un jugement biaisé. Il le rend plus crédible.
Cet article défend une thèse simple : l’IA et l’évaluation des talents ne produiront de la valeur que si l’IA cesse d’écrire à la place des managers pour aider l’organisation à observer ce qu’elle ne voyait pas — les moments où les compétences comportementales se manifestent réellement.
En résumé
L’IA appliquée à l’évaluation des talents amplifie ses biais quand elle sert à rédiger, et les corrige quand elle sert à documenter. Trois bascules à opérer : remplacer les adjectifs par des épisodes de travail, donner au collaborateur la main sur son portefeuille de preuves, et relier chaque preuve à un référentiel de compétences explicite. Le bon usage de l’IA n’est pas un meilleur stylo, c’est un meilleur observatoire.
Le piège invisible des entretiens annuels écrits par l’IA
L’argument commercial des outils d’évaluation augmentés est connu : gain de temps, harmonisation du ton, réduction de la charge mentale managériale. BCG revendique 40 % de temps gagné sur la rédaction. Les bénéfices sont réels.
Mais ils masquent un effet d’optique. Quand des managers travaillant avec des observations incomplètes utilisent le même assistant pour rédiger leurs évaluations, leurs textes convergent vers un même registre fluide et assuré. La variance — celle qui distinguait un manager rigoureux d’un manager pressé — s’efface. Tous les comptes-rendus deviennent également crédibles.
Conséquence concrète : la qualité perçue augmente pendant que la qualité réelle stagne. Les biais classiques de l’évaluation — récence, halo, affinité, rationalisation a posteriori — restent intacts, simplement mieux habillés.
Ce n’est pas un problème d’outil. C’est un problème de cible. L’IA est dirigée vers la sortie du processus (le texte final) plutôt que vers son entrée (l’observation).
Adjectifs vs épisodes : la bascule fondamentale
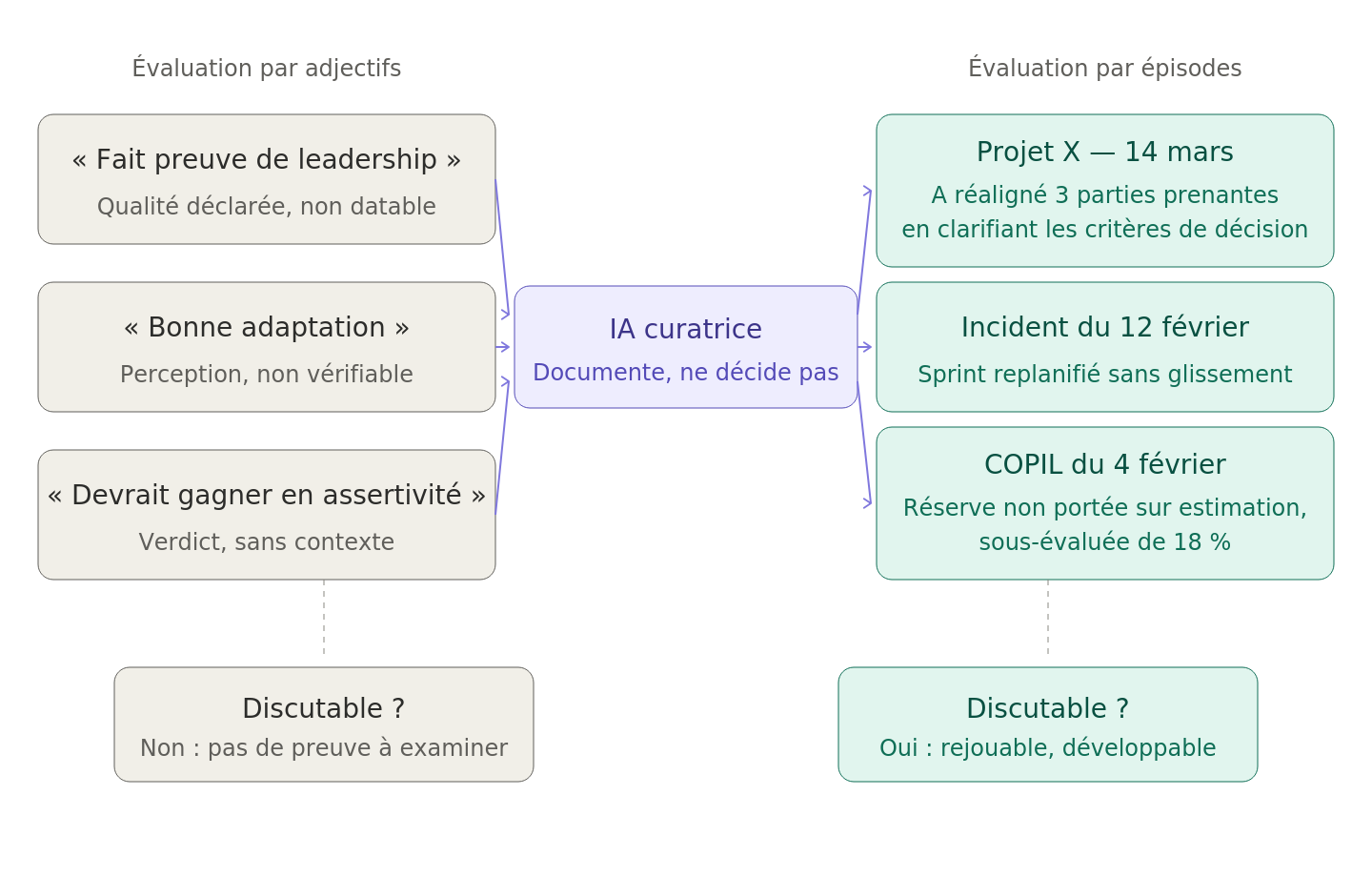
Une évaluation traditionnelle énonce des qualités. Une évaluation utile décrit des situations.
Approche par adjectifs
Approche par épisodes
« Fait preuve de leadership. »
« Lors du projet X, a réaligné trois parties prenantes en désaccord en clarifiant les critères de décision. »
« Bonne capacité d’adaptation. »
« A restructuré le planning sprint après l’incident du 12 mars, en intégrant deux contraintes nouvelles sans glisser sur la livraison. »
« Devrait gagner en assertivité. »
« En comité de pilotage du 4 février, n’a pas porté sa réserve sur l’estimation budgétaire, qui s’est révélée sous-évaluée de 18 %. »
La différence n’est pas stylistique. Elle est épistémique.
L’IA déplace le regard : de qualités déclarées vers des épisodes datés et discutables.
Dans la colonne de gauche, on évalue une perception. Dans celle de droite, on examine un comportement contextualisé, datable, discutable. C’est précisément cette bascule qui rend une évaluation développementale plutôt que verdictive : un épisode peut être rejoué, débriefé, transformé en hypothèse de progression. Un adjectif, non.
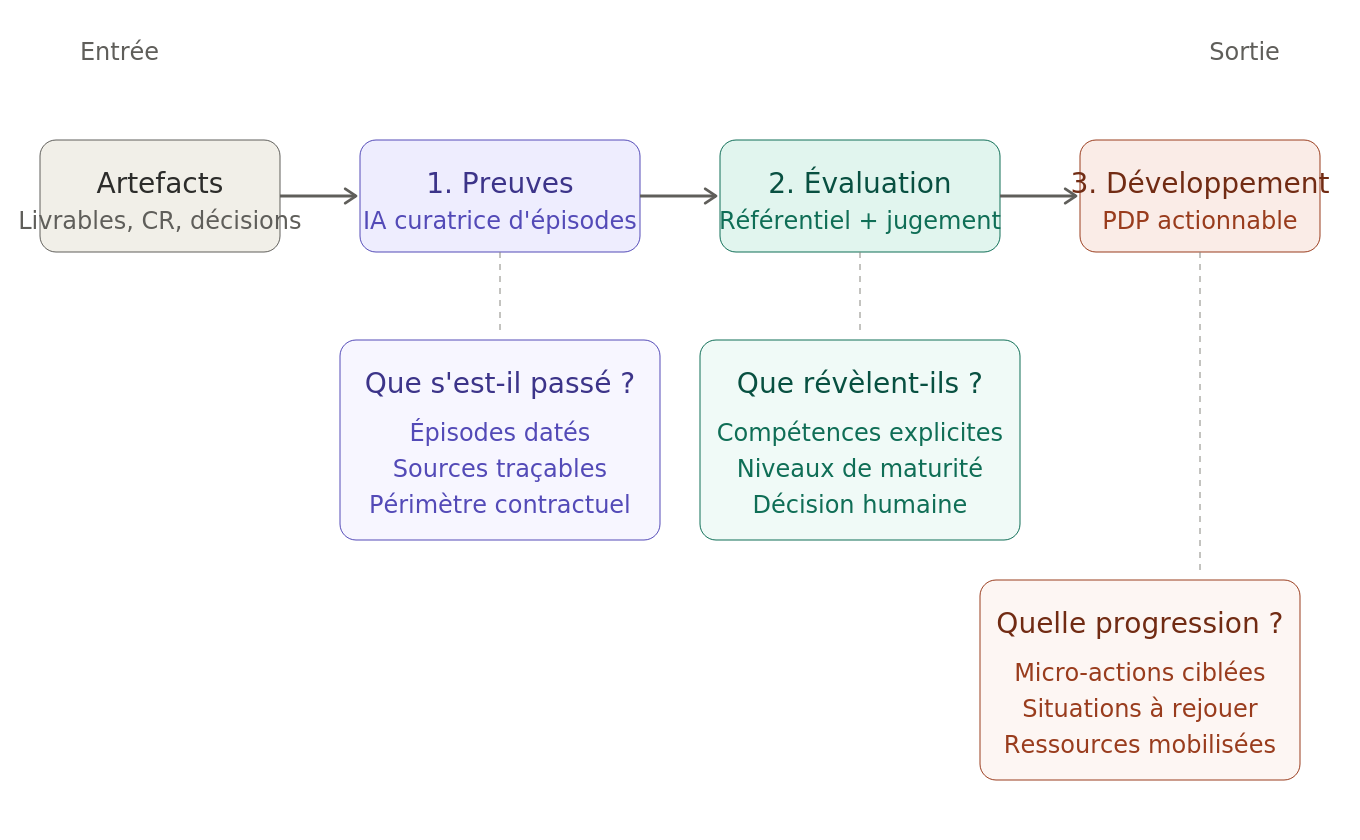
Le cadre PED : trois niveaux pour une IA utile dans l’évaluation
L’approche que nous recommandons articule trois niveaux distincts. Chacun répond à une question opérationnelle précise.
Les trois niveaux articulent la valeur de l’IA dans l’évaluation : curation des preuves, lecture par référentiel, traduction en plan de développement.
Niveau 1 — Preuves : que s’est-il réellement passé ?
L’IA est positionnée comme un agent de curation, pas comme un rédacteur. Sa tâche : parcourir les artefacts professionnels (comptes-rendus, livrables, échanges sur outils collaboratifs structurés) et faire remonter les épisodes susceptibles d’illustrer une compétence donnée.
Périmètre acceptable :
Documents de projet, rétrospectives, décisions architecturales
Comptes-rendus de réunion formalisés
Livrables clients et internes
Périmètre à exclure :
Messageries privées (DM, e-mails personnels)
Conversations informelles
Tout flux non lié à un acte professionnel formel
Chaque preuve remontée doit pointer vers sa source. Aucune note, aucune synthèse autonome.
Niveau 2 — Évaluation : quelles compétences ces preuves révèlent-elles ?
Les preuves ne valent rien sans un référentiel. Un même épisode — désamorcer un conflit en comité — peut révéler du courage managérial, de la régulation émotionnelle, du sens politique ou de l’écoute active selon le cadre de lecture appliqué.
Ce niveau exige donc une architecture de compétences explicite : définitions, comportements observables, niveaux de maturité. Sans cela, l’IA produit du bruit structuré.
C’est ici que les modèles psychométriques validés (Big Five, modèles de compétences comportementales sectoriels, référentiels 360 sur-mesure) restent indispensables. L’IA ne remplace pas la science de la mesure ; elle la rend exploitable à grande échelle.
Niveau 3 — Développement : que faire de ce qui est observé ?
Une évaluation qui s’arrête au constat est gaspillée. Le troisième niveau transforme la preuve en hypothèse de progression : micro-actions à expérimenter, situations à rejouer différemment, ressources à mobiliser.
Cette étape est celle où l’IA reprend une valeur de rédaction — mais cette fois, pour produire un plan de développement personnel ancré dans des situations identifiées, et non un texte d’appréciation flottant.
Trois garde-fous non négociables
Sans gouvernance explicite, l’évaluation augmentée par l’IA dérive vers la surveillance algorithmique. Trois règles permettent d’éviter cette pente.
1. L’IA documente, l’humain décide. Aucune note, promotion ou décision RH ne doit être générée par l’IA. La décision reste un acte managérial, contextualisé, discutable.
2. Le collaborateur conserve la main sur son portefeuille de preuves. L’IA propose des épisodes ; le collaborateur choisit ceux qu’il porte à son évaluation, peut en ajouter d’autres, et contextualise chaque preuve. Sans cette appropriation, le système est perçu — à juste titre — comme une surveillance.
3. Le périmètre des données est défini ex ante, pas découvert ex post. Quelles sources sont mobilisables ? Sur quelle profondeur historique ? Avec quelle anonymisation des tiers cités dans les artefacts ? Ces réponses doivent être contractuelles, pas implicites.
Ce que cela change pour les DRH dès lundi matin
Trois actions concrètes, applicables sans transformation lourde du SI :
Changer la question posée aux managers. Remplacer « Évaluez le leadership de X » par « Quel moment ce trimestre a le mieux révélé le leadership de X — qu’a-t-il fait, dans quel contexte, avec quel impact ? »
Inverser le rôle de l’IA dans les outils déjà en place. Au lieu de « Aide-moi à rédiger l’évaluation de X », interroger : « Trouve les trois situations du trimestre où X a influencé une décision projet. »
Préparer un référentiel de compétences exploitable par l’IA. Définitions courtes, comportements observables, exemples positifs et négatifs. Sans cela, aucune curation automatisée n’est fiable.
Le rôle d’un dispositif 360 dans cette nouvelle logique
Ce que nous décrivons ici n’est pas une rupture mais un prolongement. Les démarches de 360 feedback structurées font depuis longtemps le pari que l’évaluation gagne en justesse quand elle s’appuie sur des perspectives multiples et des comportements observables, plutôt que sur le seul jugement hiérarchique.
L’IA générative étend ce principe à un nouveau terrain : les artefacts du travail eux-mêmes. Couplée à un référentiel de compétences validé et à un plan de développement personnel assisté par IA, elle transforme l’évaluation en boucle d’apprentissage continue, là où l’entretien annuel n’était souvent qu’un rituel.
C’est la direction que nous prenons chez Praditus, en articulant 360, modèles psychométriques et plans de développement assistés par IA autour d’une même question : quelles preuves de progression votre organisation est-elle capable de voir ?
Questions fréquentes
L’IA peut-elle remplacer l’entretien annuel ?
Non. Elle peut le préparer plus finement, l’ancrer dans des situations réelles et en faire une boucle de développement plutôt qu’un rituel. La décision et la conversation restent humaines.
Quelle différence entre IA pour rédiger et IA pour documenter ?
Rédiger consiste à produire le texte final d’une évaluation. Documenter consiste à remonter les épisodes professionnels qui illustrent une compétence. La première amplifie les biais existants ; la seconde les corrige en élargissant l’observation.
L’évaluation par les preuves n’est-elle pas une forme de surveillance ?
Elle le devient si le périmètre des données n’est pas défini, si le collaborateur n’a pas la main sur son portefeuille de preuves, ou si l’IA décide à la place du manager. Les trois garde-fous décrits dans cet article sont précisément là pour éviter cette dérive.
Faut-il un référentiel de compétences pour utiliser l’IA dans l’évaluation ?
Oui. Sans architecture explicite (compétences, comportements observables, niveaux de maturité), les preuves remontées par l’IA ne sont pas interprétables. C’est ce qui distingue une démarche structurée d’une simple recherche d’exemples.
L’IA peut-elle évaluer les soft skills aussi bien qu’un manager ?
Elle n’évalue pas. Elle élargit le champ d’observation et propose des preuves. L’évaluation au sens propre — interprétation contextualisée, jugement de valeur, décision de développement — reste un acte humain.
Aller plus loin
Praditus accompagne les DRH dans la conception de dispositifs d’évaluation comportementale combinant 360 feedback, modèles psychométriques validés et plans de développement personnels assistés par IA.
Vous venez d’être invité à participer à un 360 feedback pour un collègue, un manager ou un collaborateur. Être choisi comme contributeur est un signe de confiance. Encore faut-il savoir comment répondre à un 360 feedback de manière utile, juste et constructive.